
Private Aggregation API 的关键概念
本文档的适用对象
借助 Private Aggregation API,您可以从有权访问跨网站数据的工作流中收集汇总数据。这里分享的概念对于在 Shared Storage API 和 Protected Audience API 中构建报告功能的开发者来说非常重要。
- 如果您是开发者,正在构建用于跨网站衡量的报告系统。
- 如果您是营销者、数据科学家或其他摘要报告使用者,了解这些机制有助于您做出设计决策,以检索经过优化的摘要报告。
关键词
在阅读本文档之前,建议您先熟悉关键术语和概念。下面将详细介绍这些术语。
- 汇总键(也称为“存储分区”)是一组预先确定的数据点。例如,您可能需要收集一个存储浏览器报告的国家/地区名称的位置数据存储分区。汇总键可以包含多个维度(例如,国家/地区和内容微件的 ID)。
- 可汇总的值是收集到汇总键中的单个数据点。如果您要衡量有多少法国用户查看了您的内容,则
France是汇总键中的维度,1的viewCount是可汇总的值。 - 可汇总的报告是在浏览器中生成和加密的。对于 Private Aggregation API,此字段包含与单个事件相关的数据。
- Aggregation Service 会处理可汇总报告中的数据,以创建摘要报告。
- 摘要报告是 Aggregation Service 的最终输出,其中包含噪声较大的汇总用户数据和详细的转化数据。
- worklet 是一种基础架构,可让您运行特定 JavaScript 函数并将信息返回给请求方。您可以在 worklet 中执行 JavaScript,但无法与外部网页互动或通信。
Private Aggregation 工作流
当您使用汇总键和可汇总的值调用 Private Aggregation API 时,浏览器会生成可汇总的报告。报告会发送到您的服务器,由服务器进行批量处理。汇总服务稍后会处理批量报告,并生成摘要报告。
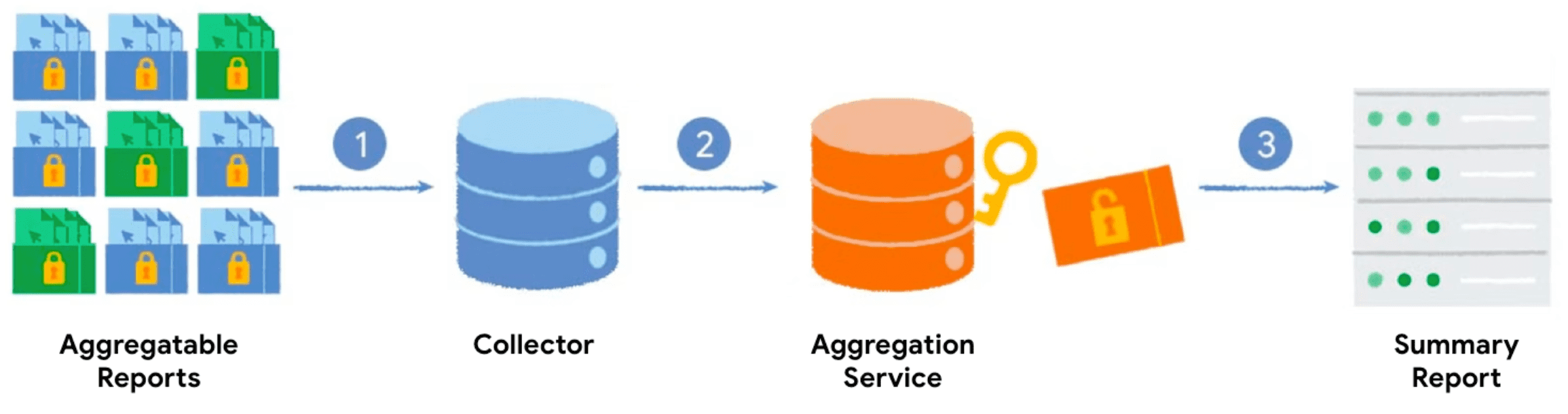
- 当您调用 Private Aggregation API 时,客户端(浏览器)会生成可汇总报告并将其发送到您的服务器进行收集。
- 您的服务器会从客户端收集报告,并将其批量发送到汇总服务。
- 收集到足够的报告后,您将对其进行批处理,并将其发送到在可信执行环境中运行的汇总服务,以生成摘要报告。
本部分介绍的工作流与 Attribution Reporting API 类似。不过,归因报告会将发生在不同时间的展示事件和转化事件收集的数据相关联。不公开汇总功能可衡量单个跨网站事件。
汇总键
汇总键(简称“键”)表示将汇总可汇总值的分桶。您可以将一个或多个维度编码到键中。维度表示您想要深入了解的某个方面,例如用户的年龄段或广告系列的展示次数。
例如,您可能在多个网站上嵌入了 widget,并希望分析查看过该 widget 的用户所在的国家/地区。您希望回答诸如“查看过我 widget 的用户中有多少来自 X 国家/地区?”之类的问题。如需针对此问题生成报告,您可以设置一个汇总键,用于编码两个维度:微件 ID 和国家/地区 ID。
向 Private Aggregation API 提供的键是 BigInt,它由多个维度组成。在此示例中,维度是 widget ID 和国家/地区 ID。假设 widget ID 最多可包含 4 位数字,例如 1234,并且每个国家/地区都映射到一个按字母顺序排列的数字,例如阿富汗是 1、法国是 61,津巴布韦是 195。因此,可汇总的键的长度为 7 位,其中前 4 位保留用于 WidgetID,后 3 位保留用于 CountryID。
假设该键表示已查看微件 ID 3276 的法国用户(国家/地区 ID 为 061)的数量,汇总键为 3276061。
| 汇总键 | |
| 微件 ID | 国家/地区 ID |
| 3276 | 061 |
您还可以使用哈希机制(例如 SHA-256)生成汇总键。例如,字符串 {"WidgetId":3276,"CountryID":67} 可以经过哈希处理,然后转换为 42943797454801331377966796057547478208888578253058197330928948081739249096287n 的 BigInt 值。如果哈希值超过 128 位,您可以对其进行截断,以确保其不会超过允许的最大分桶值 2^128−1。
在共享存储工作流中,您可以访问 crypto 和 TextEncoder 模块,它们可以帮助您生成哈希。如需详细了解如何生成哈希,请参阅 MDN 上的 SubtleCrypto.digest()。
以下示例介绍了如何根据经过哈希处理的值生成存储分区键:
async function convertToBucket(data) {
// Encode as UTF-8 Uint8Array
const encodedData = new TextEncoder().encode(data);
// Generate SHA-256 hash
const hashBuffer = await crypto.subtle.digest('SHA-256', encodedData);
// Truncate the hash
const truncatedHash = Array.from(new Uint8Array(hashBuffer, 0, 16));
// Convert the byte sequence to a decimal
return truncatedHash.reduce((acc, curr) => acc * 256n + BigInt(curr), 0n);
}
const data = {
WidgetId: 3276,
CountryID: 67
};
const dataString = JSON.stringify(data);
const bucket = await convertToBucket(dataString);
console.log(bucket); // 126200478277438733997751102134640640264n
可汇总的值
系统会对许多用户的每个键值对汇总可汇总的值,以便在摘要报告中以摘要值的形式生成汇总数据洞见。
现在,我们回到之前提出的示例问题:“有多少查看过我 widget 的用户来自法国?”此问题的答案将类似于“查看过我的微件 ID 3276 的用户中有大约 4881 位来自法国”。每个用户的可汇总值为 1,而“4881 位用户”是汇总值,即该汇总键的所有可汇总值的总和。
| 汇总键 | 可汇总的值 | |
| 微件 ID | 国家/地区 ID | 观看次数 |
| 3276 | 061 | 1 |
在此示例中,我们会针对看到该微件的每位用户将此值递增 1。在实践中,可对可汇总的值进行缩放,以提高信噪比。
贡献预算
对 Private Aggregation API 的每次调用都称为一次贡献。为保护用户隐私,我们限制从个人收集的贡献数量。
对所有汇总键中的所有可汇总值求和时,总和必须小于贡献预算。预算的范围是按工作区 origin 和每天进行划分,并且 Protected Audience API 和 Shared Storage 工作区之间的预算是相互独立的。系统会使用大约过去 24 小时的滚动时间范围来计算当天的数据。如果新的可汇总报告会导致超出预算,系统将不会创建该报告。
贡献预算由参数 L1 表示,并设置为每天每 10 分钟 216 (65,536),后备值为 220 (1,048,576)。如需详细了解这些参数,请参阅说明文档。
贡献预算的值是任意的,但噪声会按此缩放。您可以使用此预算来最大限度地提高摘要值的信噪比(详见噪声和缩放部分)。
如需详细了解贡献预算,请参阅说明。此外,如需更多指导,请参阅贡献预算。
每个报告的贡献次数上限
贡献限制可能会因调用方而异,对于共享存储空间,这些限制是可替换的默认限制。目前,为 Shared Storage API 调用方生成的报告每份报告的贡献次数上限为 20 次。另一方面,Protected Audience API 调用方每份报告的贡献次数上限为 100 次。我们之所以选择这些限制,是为了平衡可嵌入的贡献数量与载荷大小。
对于共享存储空间,单个 run() 或 selectURL() 操作中贡献的数据会批量汇总到一个报告中。对于 Protected Audience,竞价中单个来源的贡献会汇总在一起。
带内边距的贡献
贡献内容会通过内边距功能进一步修改。对载荷进行填充可保护汇总报告中嵌入的贡献真实数量的相关信息。内边距会使用 null 贡献(即值为 0)来增补载荷,以达到固定长度。
可汇总的报告
用户调用 Private Aggregation API 后,浏览器会生成可汇总报告,以供汇总服务稍后处理,以生成摘要报告。可汇总的报告采用 JSON 格式,包含加密的贡献列表,每个贡献都是一个 {aggregation key, aggregatable value} 对。可汇总报告的发送会随机延迟,最长延迟一小时。
贡献内容已加密,在汇总服务之外无法读取。汇总服务会对报告进行解密并生成摘要报告。浏览器的加密密钥和汇总服务的解密密钥由协调者(充当密钥管理服务)签发。协调者会保留服务映像的二进制哈希列表,以验证调用方是否有权接收解密密钥。
启用了调试模式的可汇总报告示例:
"aggregation_service_payloads": [
{
"debug_cleartext_payload": "omRkYXRhgaJldmFsdWVEAAAAgGZidWNrZXRQAAAAAAAAAAAAAAAAAAAE0mlvcGVyYXRpb25paGlzdG9ncmFt",
"key_id": "2cc72b6a-b92f-4b78-b929-e3048294f4d6",
"payload": "a9Mk3XxvnfX70FsKrzcLNZPy+00kWYnoXF23ZpNXPz/Htv1KCzl/exzplqVlM/wvXdKUXCCtiGrDEL7BQ6MCbQp1NxbWzdXfdsZHGkZaLS2eF+vXw2UmLFH+BUg/zYMu13CxHtlNSFcZQQTwnCHb"
}
],
"debug_key": "777",
"shared_info": "{\"api\":\"shared-storage\",\"debug_mode\":\"enabled\",\"report_id\":\"5bc74ea5-7656-43da-9d76-5ea3ebb5fca5\",\"reporting_origin\":\"https://localhost:4437\",\"scheduled_report_time\":\"1664907229\",\"version\":\"0.1\"}"
您可以在 chrome://private-aggregation-internals 页面中检查可汇总报告:

出于测试目的,您可以使用“发送所选报告”按钮立即将报告发送到服务器。
收集和批量处理可汇总报告
浏览器使用所列的知名路径,将可汇总的报告发送到包含对 Private Aggregation API 的调用的 worklet 的来源:
- 对于 Shared Storage:
/.well-known/private-aggregation/report-shared-storage - 对于 Protected Audience:
/.well-known/private-aggregation/report-protected-audience
在这些端点上,您需要运行一个服务器(充当收集器),用于接收从客户端发送的可汇总报告。
然后,服务器应将报告分批并将批量数据发送到汇总服务。根据可汇总报告的未加密载荷中提供的信息(例如 shared_info 字段)创建批次。理想情况下,每个批次应包含 100 份或更多报告。
您可以选择每天或每周批量处理。此策略非常灵活,您可以针对预计会带来更多流量的特定事件(例如,预计会带来更多展示次数的年份日期)更改批量处理策略。批处理应包含使用相同 API 版本、报告来源和安排报告时间的报告。
过滤条件 ID
借助 Private Aggregation API 和 Aggregation Service,您可以使用过滤 ID 在更精细的级别(例如按广告系列)处理衡量结果,而不是在更大规模的查询中处理结果。

如需立即开始使用,请参考以下粗略步骤,将其应用于您的当前实现。
共享存储空间步骤
如果您在流程中使用 Shared Storage API:
定义您将在何处声明和运行新的 Shared Storage 模块。在以下示例中,我们将模块文件命名为
filtering-worklet.js,并在filtering-example下注册。(async function runFilteringIdsExample () { await window.sharedStorage.worklet.addModule('filtering-worklet.js'); await window.sharedStorage.run('filtering-example', { keepAlive: true, privateAggregationConfig: { contextId: 'example-id', filteringIdMaxBytes: 8 // optional } }}); })();请注意,
filteringIdMaxBytes可按报告进行配置,如果未设置,则默认为 1。此默认值旨在防止不必要地增加载荷大小,从而降低存储和处理费用。如需了解详情,请参阅灵活付款说明。在
filtering-worklet.js中,当您在“Shared Storage”Worklet 中将贡献内容传递给privateAggregation.contributeToHistogram(...)时,可以指定过滤 ID。// Within filtering-worklet.js class FilterOperation { async run() { let contributions = [{ bucket: 1234n, value: 56, filteringId: 3n // defaults to 0n if not assigned, type bigint }]; for (const c of contributions) { privateAggregation.contributeToHistogram(c); } … } }); register('filtering-example', FilterOperation);可聚合报告将发送到您定义的端点
/.well-known/private-aggregation/report-shared-storage。请继续参阅过滤 ID 指南,了解需要对汇总服务作业参数进行哪些更改。
批处理完成并发送到已部署的汇总服务后,过滤后的结果应会反映在最终摘要报告中。
Protected Audience 步骤
如果您在流程中使用 Protected Audience API:
在您当前的 Protected Audience 实现中,您可以设置以下内容以钩入 Private Aggregation。与共享存储空间不同,目前还无法配置过滤 ID 的大小上限。默认情况下,过滤 ID 的大小上限为 1 字节,并将设置为
0n。请注意,这些参数将在 Protected Audience 报告函数(例如reportResult()或generateBid())中设置。const contribution = { ... filteringId: 0n }; privateAggregation.contributeToHistogram(contribution);可聚合报告将发送到您定义的端点
/.well-known/private-aggregation/report-protected-audience。批处理完成并发送到已部署的汇总服务后,过滤后的结果应会反映在最终摘要报告中。以下是 Attribution Reporting API 和 Private Aggregation API 的说明以及初始提案。
请继续阅读汇总服务中的过滤 ID 指南,或前往 Attribution Reporting API 部分,了解更详细的说明。
汇总服务

汇总服务会从收集器接收经过加密的可汇总报告,并生成摘要报告。如需详细了解如何在收集器中批处理可汇总报告,请参阅我们的批处理指南。
该服务在可信执行环境 (TEE) 中运行,可确保数据完整性、数据机密性和代码完整性。如果您想详细了解如何将协调者与 TEE 搭配使用,请详细了解其角色和用途。
摘要报告
通过摘要报告,您可以查看添加了噪声的收集数据。您可以请求针对给定一组密钥生成摘要报告。
摘要报告包含一组 JSON 字典式键值对。每个对包含:
bucket:汇总键(以二进制数字字符串表示)。如果使用的汇总键为“123”,则存储分区为“1111011”。value:指定衡量目标的摘要值,是从所有可汇总的报告中汇总得出,并添加了噪声。
例如:
[
{"bucket":` `"111001001",` `"value":` `"2558500"},
{"bucket":` `"111101001",` `"value":` `"3256211"},
{"bucket":` `"111101001",` `"value":` `"6536542"},
]
噪声和缩放
为保护用户隐私,Aggregation Service 会在每次请求摘要报告时,向每个摘要值添加一次噪声。噪声值是从拉普拉斯概率分布中随机抽取的。虽然您无法直接控制添加噪声的方式,但可以影响噪声对衡量数据的影响。
无论所有可汇总值的总和如何,噪声分布都是相同的。因此,可汇总的值越高,噪声的影响就越小。
例如,假设噪声分布的标准差为 100,且中心为 0。如果收集的可汇总报告值(或“可汇总值”)仅为 200,则噪声的标准差将为汇总值的 50%。但是,如果可汇总的值为 2 万,则噪声的标准差只会占汇总值的 0.5%。因此,可汇总的值为 2 万时,信噪比会高得多。
因此,将可汇总的值乘以缩放比例有助于减少噪声。缩放比例表示您希望对给定可汇总值进行的缩放比例。

通过选择较大的放大系数来放大值可以减少相对噪声。不过,这也会导致所有广告系列所带来的贡献总和更快达到贡献预算上限。通过选择较小的缩放系数常量来缩小值会增加相对噪声,但会降低达到预算上限的风险。

如需计算适当的放大系数,请将贡献预算除以所有键的可汇总值的最大总和。
如需了解详情,请参阅贡献预算文档。
互动和分享反馈
Private Aggregation API 正在积极讨论中,未来可能会发生变化。如果您试用此 API 并有反馈,我们非常期待收到您的反馈。
- GitHub:阅读说明文档,提出问题并参与讨论。
- 开发者支持:在 Privacy Sandbox 开发者支持代码库中提问和参与讨论。
- 加入 Shared Storage API 群组和 Protected Audience API 群组,及时了解与 Private Aggregation 相关的最新公告。